The Validator’s Paradox: Why Probabilistic Systems Cannot Truly Validate Each Other
May 22, 2026

This article examines the growing reliance on multi-agent AI architectures in enterprise AI systems and challenges the assumption that probabilistic models can reliably validate one another. It explains how large language models operate through statistical prediction rather than deterministic truth, creating inherent limitations in AI-based verification chains. The article explores concepts such as infinite regression, correlated AI failures, hallucination reinforcement, and structured confidence illusions within enterprise AI pipelines. It also highlights the critical importance of deterministic validation systems, rules engines, schema enforcement, retrieval verification, and human-in-the-loop oversight for high-trust domains such as legal AI, finance, healthcare, and compliance. The article ultimately advocates for hybrid AI architectures that combine probabilistic reasoning with deterministic grounding and human accountability to build reliable enterprise AI systems.
What We Mean by Probabilistic

Large Language Models (LLMs) do not operate on objective truth. They operate on probability. Given an input, an AI model generates the statistically most likely continuation based on patterns learned from massive training datasets, reinforced through fine-tuning, and calibrated using Reinforcement Learning from Human Feedback (RLHF).
This is not a flaw in artificial intelligence systems. It is the foundational architecture of modern generative AI. For tasks such as content generation, text summarisation, information extraction, and reasoning assistance, this probabilistic design is highly effective and often extremely useful.
However, it is important to understand that every output generated by a large language model is fundamentally a prediction. It is not an independently verified fact or a guaranteed conclusion. It is a high-confidence probabilistic response based on learned linguistic patterns.
This distinction becomes critical when organizations introduce a so-called “critic agent” or secondary AI verification system to validate model outputs. In reality, the critic agent is itself another probabilistic system evaluating the first. It does not possess access to objective ground truth. Instead, it relies on its own internal probability distributions, shaped by similar training data, comparable reasoning pathways, and often identical limitations.
As a result, adding a second AI agent does not automatically create true verification. It introduces another statistically informed opinion generated by a related machine learning system. Understanding this limitation is essential for anyone deploying AI tools, especially in high-stakes environments such as law, healthcare, governance, or financial decision-making.
The Problem of Infinite Regression
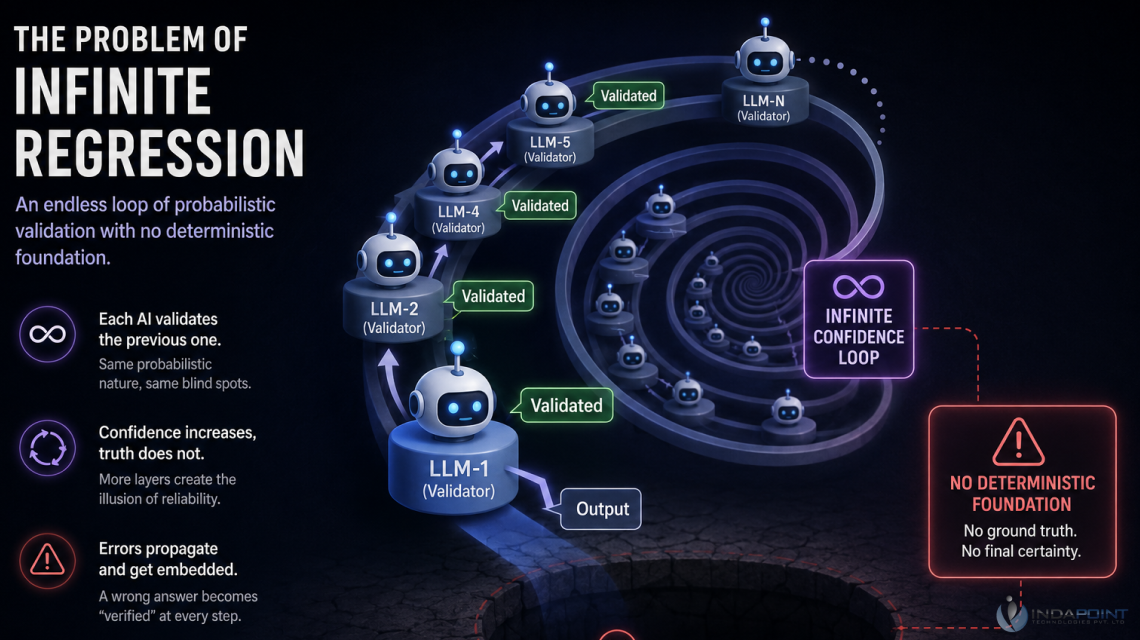
In modern multi-agent AI systems, the concept of validation becomes philosophically and operationally uncomfortable. If organizations cannot fully trust the output generated by one large language model (LLM), they often introduce another AI model to validate it. However, if that second model is also probabilistic, the same reliability problem still exists. This creates the classic philosophical issue of infinite regression — an endless chain of validation where no layer ever reaches a truly deterministic foundation. In many enterprise AI architectures, this regress problem is increasingly being mistaken for reliability simply because multiple AI agents are involved in the workflow.
Every additional validation layer may make the AI pipeline appear more sophisticated and trustworthy, but the underlying probabilistic behavior of each model remains unchanged. The result is an infinite confidence loop, where outputs appear increasingly reliable despite lacking genuine deterministic verification. In practice, these AI validation chains can amplify errors instead of preventing them. When one agent produces a convincing but incorrect response and another agent validates it using similar reasoning patterns or training assumptions, the error becomes embedded as “verified” output across the system.
This represents one of the biggest reliability challenges in enterprise AI engineering and LLM production systems. Most AI models share overlapping datasets, reasoning heuristics, and hallucination patterns, leading to highly correlated failures rather than independent verification. As a result, polished outputs and high confidence scores should never be confused with factual correctness. This distinction is especially critical in high-stakes industries such as legal AI, healthcare, finance, compliance, and enterprise decision-making systems, where even small validation failures can create serious real-world consequences.
The Correlated Failure Problem

One of the most overlooked risks in modern multi-agent AI systems is the problem of correlated failure. Most enterprise large language models (LLMs) used in AI validation pipelines are trained on highly overlapping internet-scale datasets, inherit similar reasoning heuristics, and develop comparable shortcut patterns during training. As a result, these models often hallucinate in remarkably similar ways and tend to reinforce assumptions generated earlier in the workflow instead of independently challenging them. This creates a major reliability issue within enterprise AI architectures, where multiple AI agents may appear to provide independent validation while actually sharing the same underlying probabilistic behavior.
In many AI agent systems, critic or verification agents are frequently built using the same model family as the primary reasoning agent they are evaluating. This means the reviewer is not truly independent. Instead, it resembles a person reviewing their own work shortly after writing it — the blind spots, reasoning biases, overconfidence patterns, and tendency to accept fluent-sounding responses remain largely unchanged. While the output may appear more structured and authoritative after multiple validation passes, the underlying weaknesses of the system often remain fully intact.
True verification in enterprise AI engineering requires architectural diversity, including different datasets, alternative reasoning systems, deterministic validation layers, and independent logic structures. However, most multi-agent AI pipelines do not provide this level of independence. Instead, they create the illusion of reliable verification while operating on the same probabilistic foundation across every layer of the workflow. This is why organizations deploying production-grade AI systems must combine probabilistic AI reasoning with deterministic validation systems, observability infrastructure, and human oversight to achieve genuinely reliable AI operations at scale.
Human in the Loop: Not a Workaround — a Requirement

One of the most overlooked risks in modern multi-agent AI systems is the problem of correlated failure. Most enterprise large language models (LLMs) used in AI validation pipelines are trained on highly overlapping internet-scale datasets, inherit similar reasoning heuristics, and develop comparable shortcut patterns during training. As a result, these models often hallucinate in remarkably similar ways and tend to reinforce assumptions generated earlier in the workflow instead of independently challenging them. This creates a major reliability issue within enterprise AI architectures, where multiple AI agents may appear to provide independent validation while actually sharing the same underlying probabilistic behavior.
In many AI agent systems, critic or verification agents are frequently built using the same model family as the primary reasoning agent they are evaluating. This means the reviewer is not truly independent. Instead, it resembles a person reviewing their own work shortly after writing it — the blind spots, reasoning biases, overconfidence patterns, and tendency to accept fluent-sounding responses remain largely unchanged. While the output may appear more structured and authoritative after multiple validation passes, the underlying weaknesses of the system often remain fully intact.
True verification in enterprise AI engineering requires architectural diversity, including different datasets, alternative reasoning systems, deterministic validation layers, and independent logic structures. However, most multi-agent AI pipelines do not provide this level of independence. Instead, they create the illusion of reliable verification while operating on the same probabilistic foundation across every layer of the workflow. This is why organizations deploying production-grade AI systems must combine probabilistic AI reasoning with deterministic validation systems, observability infrastructure, and human oversight to achieve genuinely reliable AI operations at scale.
A Better Architecture: Hybrid Validation

The solution to the reliability challenges in modern multi-agent AI systems is not to abandon probabilistic AI architectures entirely, but to clearly understand what large language models (LLMs) can and cannot reliably do. Enterprise AI teams must design validation layers based on the strengths and limitations of probabilistic systems rather than assuming that additional AI agents automatically create trustworthy verification. Effective enterprise AI architecture depends on separating tasks that benefit from probabilistic reasoning from tasks that require deterministic validation and structured control systems.
In practical AI engineering workflows, LLMs are exceptionally effective for tasks involving ambiguity, language understanding, and contextual reasoning. This includes information extraction from unstructured documents, large-scale summarization and synthesis, reasoning assistance, hypothesis generation, workflow acceleration, and natural language interfaces. These capabilities make probabilistic AI systems highly valuable for improving productivity, reducing manual effort, and helping organizations process massive volumes of information more efficiently across enterprise environments.
However, validation and enforcement layers require a fundamentally different approach. Critical functions such as rules engines, policy enforcement, schema validation, mathematical verification, database integrity checks, retrieval validation, regulatory compliance systems, and final human approval checkpoints must remain deterministic. Unlike probabilistic AI systems, deterministic systems operate on fixed logic, explicit constraints, and verifiable rules, making them essential for maintaining reliability, consistency, compliance, and operational safety in production-grade AI systems.
This separation between probabilistic reasoning and deterministic validation is not a compromise in modern AI engineering strategy. It is a recognition that different categories of problems require different forms of verification. Probabilistic reasoning excels in context-rich and ambiguous workflows, while deterministic systems remain essential for validating facts, figures, compliance boundaries, and high-stakes operational decisions. The future of reliable enterprise AI systems will depend on combining these two approaches effectively rather than treating them as competing paradigms.
The Dangerous Illusion of Structured Confidence

What makes modern multi-agent AI architectures concerning is not that the concept itself is fundamentally flawed, but that these systems often create outputs that appear highly structured, polished, and professionally validated without actually achieving true verification. In many enterprise AI systems, outputs pass through multiple layers such as Planner agents, Executor agents, Critic agents, Reflection agents, and Verification agents. By the end of this workflow, the result carries an implicit sense of authority. The pipeline appears rigorous, the formatting looks precise, the reasoning feels structured, and the confidence scores often seem convincing to end users and enterprise stakeholders.
However, beneath this sophisticated presentation layer, every stage of the workflow still relies on probabilistic AI reasoning. Each agent within the pipeline generates statistically likely continuations rather than deterministic truths. While the validation chain may become longer and more complex, the core verification gap remains unresolved because none of the agents are truly grounded in deterministic validation mechanisms. This creates a major challenge for enterprise AI reliability, particularly in high-stakes production environments where perceived confidence can easily be mistaken for factual correctness.
This phenomenon represents the core of the Validator’s Paradox in modern AI engineering. The more validation agents organizations add to a workflow, the more reliable and trustworthy the system appears externally, even though the underlying probabilistic nature of the architecture has not fundamentally changed. Instead of creating genuine verification, many multi-agent systems create the illusion of reliability through structured orchestration, layered reasoning, and increasingly polished outputs.
For organizations building production-grade AI infrastructure, this distinction is critically important. Structured outputs, clean formatting, and multiple validation layers should not be confused with deterministic correctness. Reliable enterprise AI architectures require grounding through deterministic systems, retrieval verification, observability infrastructure, rules-based enforcement, and human oversight rather than relying solely on probabilistic agents validating other probabilistic agents.
What Reliable AI Actually Looks Like

The future of reliable AI systems will not be defined by adding more agents into enterprise workflows, but by building stronger AI grounding, deterministic validation, and accountability mechanisms across modern AI infrastructures. Organizations deploying multi-agent AI architectures must clearly understand the difference between tasks where probabilistic AI systems are highly effective and scenarios where external anchoring, structured governance, and human oversight become essential. As enterprise AI infrastructure grows increasingly complex, businesses are recognizing that deterministic checkpoints, compliance frameworks, and validation systems must function as core architectural layers rather than optional safeguards added later in development.
In high-stakes industries such as legal AI, healthcare AI, financial AI systems, and enterprise governance, maintaining human-in-the-loop (HITL) AI systems is no longer viewed as a temporary operational limitation. Instead, human oversight is becoming a permanent structural requirement for ensuring accountability, contextual reasoning, ethical evaluation, and production-grade reliability. While large language models (LLMs) can significantly improve workflow automation, accelerate reasoning processes, and reduce operational burden, these systems still operate through statistical prediction rather than deterministic truth verification.
Modern AI engineering strategies are increasingly shifting toward hybrid enterprise architectures where AI systems assist human judgment instead of fully replacing it. An AI-assisted workflow supported by deterministic validation systems, governance controls, schema enforcement, retrieval verification, and structured human review is often far more reliable than a fully autonomous multi-agent pipeline that merely creates the appearance of certainty through layered probabilistic outputs. This transition reflects a growing realization across the enterprise AI ecosystem: operational trustworthiness matters more than architectural complexity.
As organizations continue scaling enterprise AI deployments, the focus is moving away from building visually impressive agent chains and toward designing systems that are observable, grounded, verifiable, and operationally sustainable. The solution to the Validator’s Paradox lies in balancing probabilistic reasoning with deterministic safeguards, compliance frameworks, and accountable human decision-making. Ultimately, the future of AI reliability, responsible AI architecture, and enterprise AI governance will depend on building systems that augment human intelligence while maintaining clear validation boundaries, transparency, and trustworthy oversight mechanisms.
Conclusion
The future of reliable enterprise AI will not be defined by how many agents exist within a workflow, but by how effectively those systems are grounded in deterministic validation and human accountability. Multi-agent AI architectures can improve workflow orchestration, reasoning assistance, and operational efficiency, but they cannot independently guarantee truth, correctness, or reliability when every layer in the chain remains probabilistic. The Validator’s Paradox highlights a fundamental reality of modern AI engineering: confidence is not the same as verification. As enterprise AI systems continue scaling across legal, financial, healthcare, and operational domains, organizations must design architectures that combine probabilistic intelligence with deterministic safeguards, observability systems, compliance logic, and human oversight. Ultimately, trustworthy AI will emerge not from endlessly stacking validation agents, but from building balanced AI systems where probabilistic reasoning, deterministic verification, and accountable human judgment work together as complementary layers of reliability.





